
机器学习
机器学习
基础或专业术语
数据集(Training Set)
用于训练模型的数据集合,一般具有输入特征(x = "input" variable feature)输出特征(y = "output" variable or "target" variable)序号(m = number of training examples)。输入输出构成一条训练数据(x,y) = single training examples。(x,y)之上可以加上^(i),用于表示这是第几个训练数据:比如
输入输出和函数
机器学习中函数(Model)一般用f表示,输入(feature)常为x,真实输出为y,我们预测的输出(prediction)为(表示输入x通过函数的预测输出值)
如何计算模型f
我们以线性模型举例: 我们要求模型f,实际就是要求w和b(即模型参数或者权重)的值。w和b一般就是基于x和来求得。
代价函数公式(cost function也可以叫成本函数)
或者
所以我们要找到w,b满足:
代价函数就是来计算当前预测值和真实值y之间的差异.
常用的是平方误差代价函数:
或者
这里使用2m是为了让计算更简洁,后续求权重偏导的过程中会出现一个2,在这里正好可以约去。
我们求模型的目标也就是让这个J尽可能地合理地小一些.
所以不同的权重比如w,b会有不同的J,J值与权重的映射又组成了一个函数,我们需要在这个函数中寻找J最小值所对应的权重。
可视化代价函数
可以建立一个3D图,或者使用等高线来表示。
梯度下降(gradient decent)
所以我们要找到合适的权重就是要找到尽可能小并且合适的J,那么这就需要用一个代码可编写的算法来寻找,这就是梯度下降算法。
我的理解就是,从J函数某个位置开始作为起点,根据导数去寻找J的最小值(导数为0),要注意的是,J函数可能有多个极小值点,所以不同的起点找到的值可能不同。
算法函数:
: 权重参数 (Weight)。左侧的 是更新后的值,右侧是当前值。
(Alpha): 学习率 (Learning rate)。它决定了我们沿着梯度方向“迈步”的大小。: 偏导数 (Derivative)。它代表了代价函数 在当前 点处的斜率,指明了函数值上升最快的方向。
同理对于其他权重,比如b也有:
要注意的是在实际的梯度下降过程中,所有的权重是同步变化的,变化顺序就要准确获取,如下:
可见w和b是同步更新的,而不是一个更新再应用到另一个
学习率
可以理解为步长,即每次梯度下降的变化量大小。如果学习率比较大,那么值在进行梯度下降的时候一次走的值就会很大,可能会跳过一些合适的值;但是如果学习率很小,每次走的步长很小,寻找过程就会很慢。
所以我们应该寻找一个合适的学习率,或者让学习率能够采用自适应策略:因为越接近J的最小值,导数会越小,那么此时走的步长就应该小一些,此时可以让学习率根据导数的大小来变化。
利用上述公式进行计算:
监督学习(Supervised learning 带有输入x和输出y)
- 回归算法(Regression Model)(常用于预测数据,输出有无数种可能)
- 分类算法(Classification Model)(顾名思义,用于分类,预测出的数据即为类别,少数可能的输出)
线性回归模型(Liner Regression Model)(监督学习中的回归算法)
输入只有一个维度,比方说房子的大小,输出也是一个维度,比方说房价。房价与房子大小之间的关系可以用一条线性函数来表示,通过两者关系的数据集可以拟合出一条合理的线性模型,这条线性模型就可以用来预测房价,即属于回归算法,
无监督学习(Unsupervised learning 只有输入x没有输出y,没有数据监督)
- 聚类算法(自己根据特征将其进行分类)
- 异常检测 (根据输入数据的特征寻找出异常的数据)
- 降维(将一个大的数据集压缩到小的数据集,但是尽可能多的保留信息)
多维
多维特征
实际的模型肯定不会像用房子大小预测房价一样,只有一个大小的特征。实际的模型肯定有很多特征feature(比如:房子大小、:浴室数量、:楼层数量、:已用年龄等等),一条这样的横向数据构成一个横向量。那么现在我们要有符号表示哪一个特征:
可以理解为n为一条数据有几个输入作为特征。i表示第几条数据,j表示第几个特征。
最后这个多维线性模型:
向量化
或者叫矢量化,能让代码更简洁,运行起来更快(有GPU)。
example:
在python代码中可以用一个线性代数库NumPy来将列表转化为numpy的array(向量对象)
import numpy as np
w = np.array([1.0, 2.5, -3.3])
b = 4
x = np.array([10, 20, 30])
#我们要计算点积可能会想到用一个循环来求和,如下:
# f = 0
# for j in range(n):
# f = f + w[j] * x[j]
# f = f + b
#但是并不够简洁,numpy给我们提供了更简洁的函数
f = np.dot(w,x) + b使用向量化进行计算实际上是更快的,因为循环是一个串行的操作,但是dot函数会并行计算点积,最后将点积相加。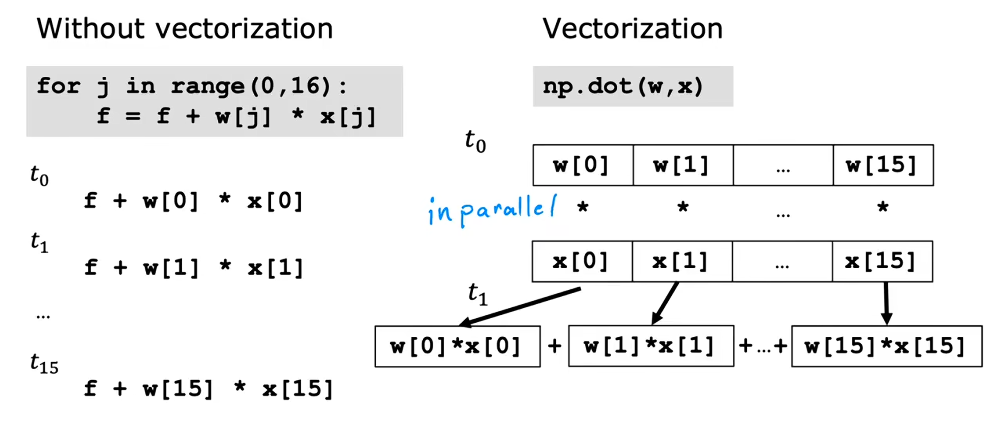
所以向量化后,很多计算都是并行处理的,会快很多。
多元线性回归的梯度下降
在多元场景下,每个参数 的更新都需要用到对应的特征分量 。
权重 的更新
偏置 的更新
特征放缩
能够让梯度下降运行更快的一种算法。
简单来说,特征放缩就是为了把形状怪异的“深谷”变成圆润的“碗”:如果特征范围差距过大(如面积 2000 对比卧室数 2),损失函数的等高线会变得极其扁长,导致梯度下降在寻找最优解时反复震荡、走弯路;通过放缩让各特征处于同一数量级,能让算法走直线、不跑偏,从而极大地加快模型收敛的速度。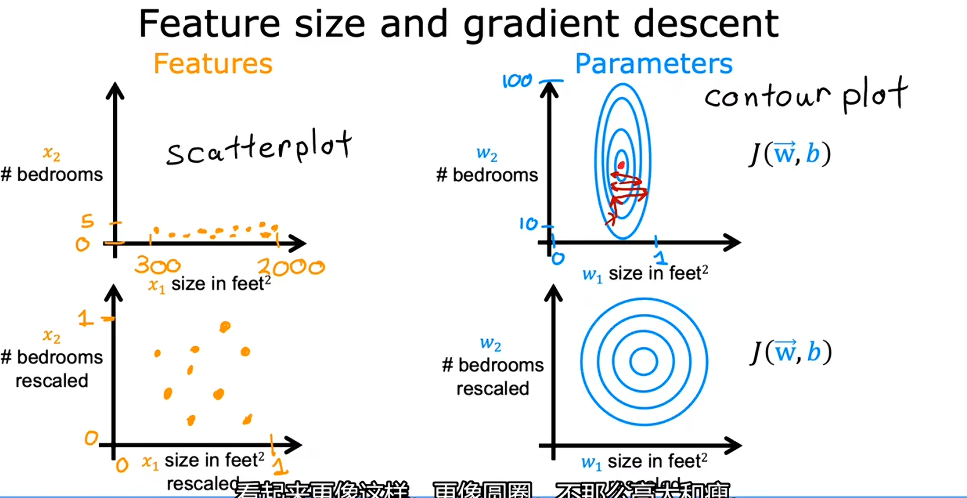
特征放缩算法
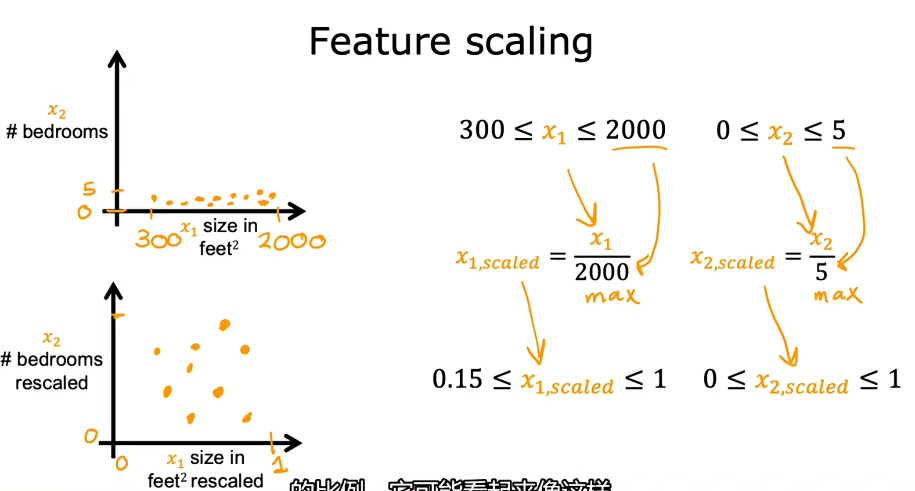
- Feature scaling:将特征范围都除以最大值,这样特征范围最大值就会被限制在1。
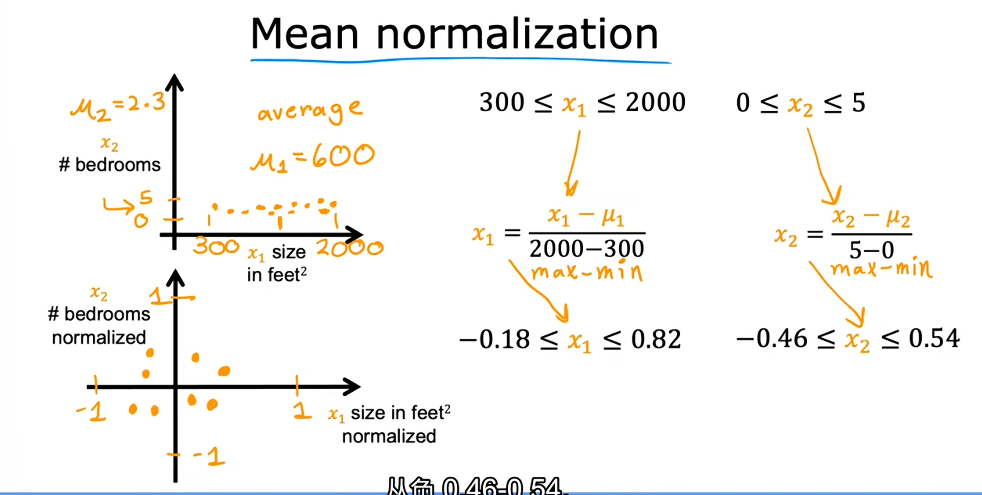
- Mean normalization(均值归一化):取特征的平均值,对于每个特征值都如此计算 这样的话特征范围就被限制在-1到1
- Z-Score normalization:计算每个特征的标准差,对于每个特征值都计算.
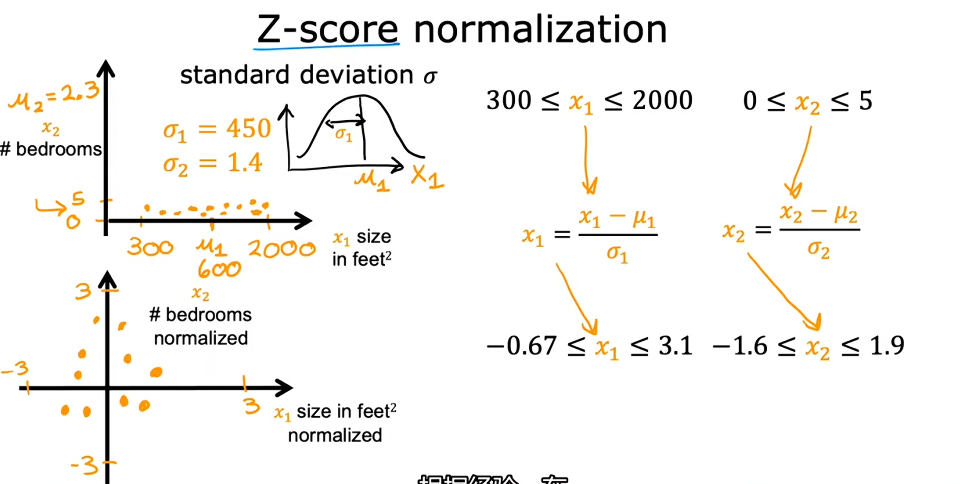
放缩后各个特征范围尽量相仿并且合理较小,如果某个特征范围相对较大或者过小可以继续对其进行放缩。
判断梯度下降是否收敛(converging)
以代价函数值为纵坐标,以梯度下降迭代次数为横坐标的函数曲线图称为学习曲线,一般来说J要随着迭代次数逐渐减小。如果这个曲线随着迭代次数有增加,说明学习率不合适(过大)或者代码出现错误。
经过多次迭代之后,这个学习曲线就会收敛到一个较小的值,但是我们一开始并不知道迭代次数,所以要确定模型何时收敛一种方法是建立所说的学习曲线,另一种则是使用自动收敛测试(Automatic convergence test)。
自动收敛测试:让代表一个较小值,比如0.001,如果一次迭代之后J的减小值比这个还要小,你就可以确定收敛了,但是要找到一个合适的是比较困难的,所以更多情况下可以用学习曲线.
如何设置一个比较好的学习率
之前我们学到了,学习率太大会导致学习曲线不能收敛,在谷间波荡,太小又会导致收敛速度过慢。当学习曲线一直是增加的时候,有可能是学习率设置太大了,也有可能是代码出错了(把-写成了+),这个时候可以设一个较小的学习率来测试一下,如果还是一直增加,大概率就是代码问题。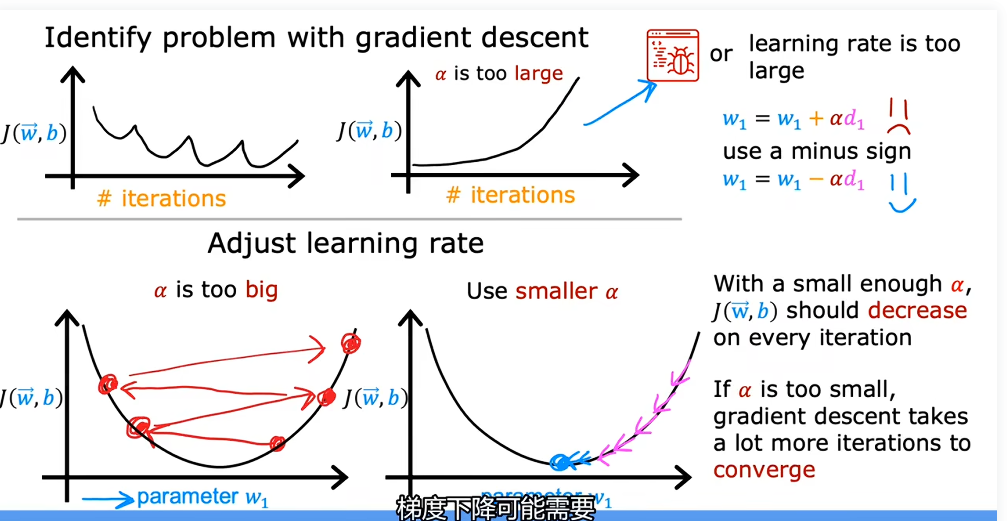
实际训练过程中可能会选择多个学习率的值,从较小的开始尝试,每次放大几倍,找到比较合适的学习率。
特征工程(Feature Engineering)
还是以预测房价举例,一个房子的房价可能跟它的长和宽有关系,但是实际上更跟面积即长乘宽有关系,这个时候特征就变成了一个。
新建一个特征就是特征工程的一个例子,能够让算法更简单。
多项式回归
用来拟合非线性的方程,不同的数据,应当选择合适的多项式函数来进行拟合,??
逻辑回归算法(logistic regression)
虽然叫逻辑回归但是实际上不算是回归模型,跟之前我们学到的一样,回归模型一般是用来预测数据的,范围比较大,这个命名是历史原因,不用管。
线性回归并不是一个解决分类问题的好算法,他表示的是一个大范围的数值,而分类是几个可能的数值,这就需要我们引入逻辑回归。
比较简单的分类只有两种情况,true和false,在计算机中用1和0表示,也可以称为positive clas和negative class(不是语义上的)。
实际训练过程中,模型也可能是一个线性的,输出数据可能千奇百怪,这个时候我们需要设置一个阈值,比如0.5,让小于0.5置为0,大于0.5置为1.此时我们需要引入sigmoid函数或者称为logistic函数:
这就是逻辑回归的精髓: 先用线性模型计算出一个“得分” ,再用 Sigmoid 函数把这个得分“压”进 0 到 1 的概率区间里。 的作用:压制范围(映射)。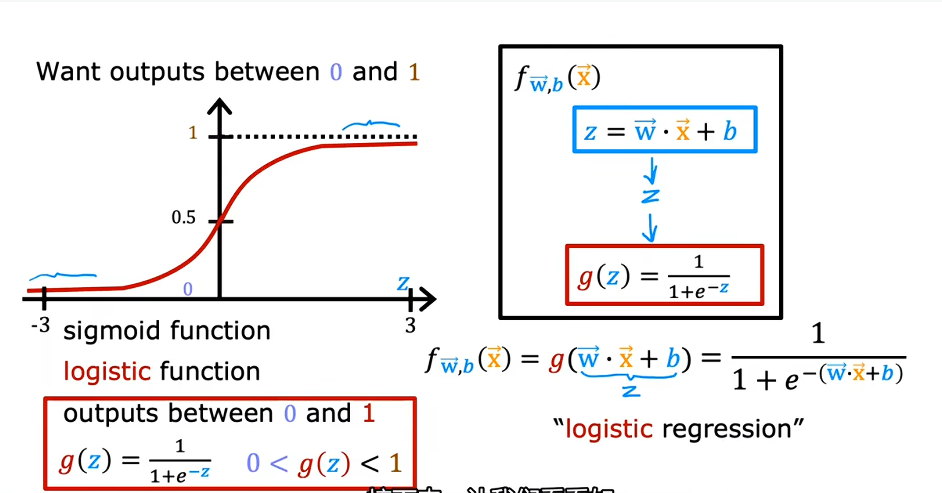
决策边界(Decision boundary)
我们sigmoid函数将数值映射为分类概率,那么我们就要知道映射概率的边界,什么范围的映射概率到哪个分类。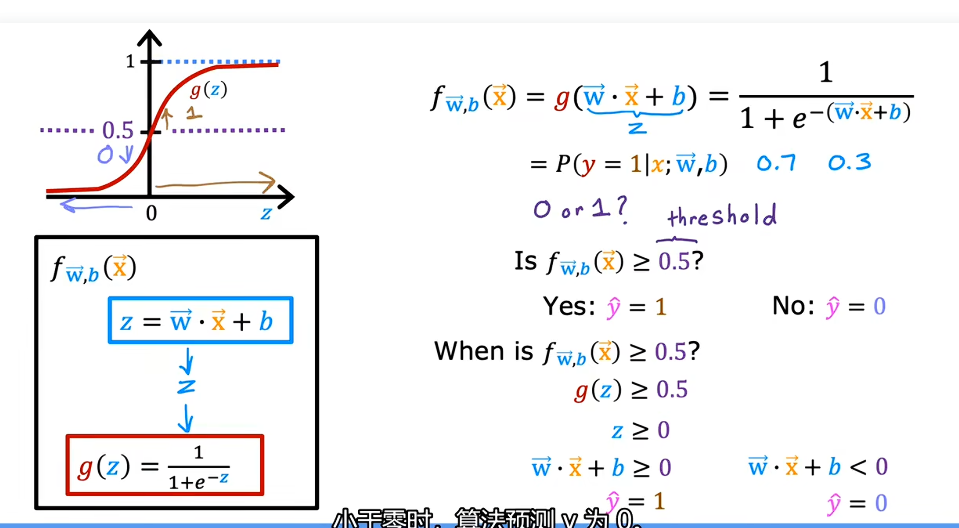
一般来说g(z) = 0.5为边界,当g(z)大于等于0.5时,分类为1,g(z)小于0.5时分类为0.再根据,z >= 0时分类为1,z < 0时,分类为0.
决策边界是画在你的原始数据图(比如 为横轴, 为纵轴的图)里的。它是用来告诉你在特征空间里,哪块地盘属于 A,哪块地盘属于 B。比如: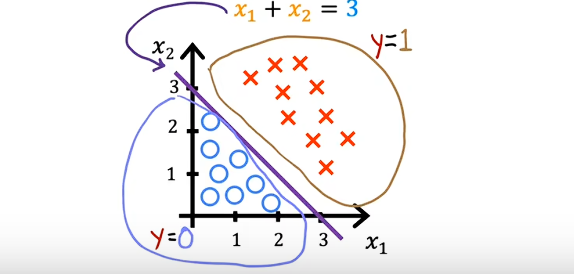

实际的决策边界可能是各种形状。
逻辑回归模型中的代价函数
在线性回归模型中,代价函数是一个凹陷的函数只有一个极小值,公式是使用平方差求和但是对于逻辑回归模型若用相同的方法进行求成本函数,你会发现逻辑回归的成本函数变成了一个多极小值的凹凸不平的函数,并不合要求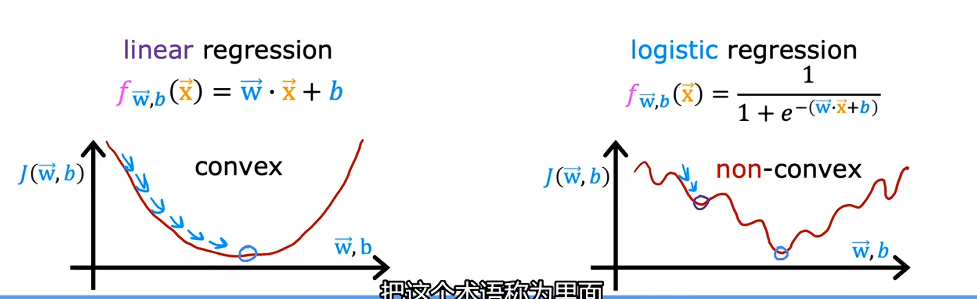
所以我们要用一个新的成本函数:the loss on a single training example,我们称其为损失函数。
我们可以来看看L的两个分叉
因为sigmoid函数概率只能取到0-1,所以定义域也就确定了,当实际值y为1的时候,如果我们预测的也是1,那么根据L,此时代价是0,没有惩罚,但是如果我们的预测值是0,那么根据L,代价就是无穷大,惩罚严重。
同理,当实际值为0时,对对数函数进行变化,如下: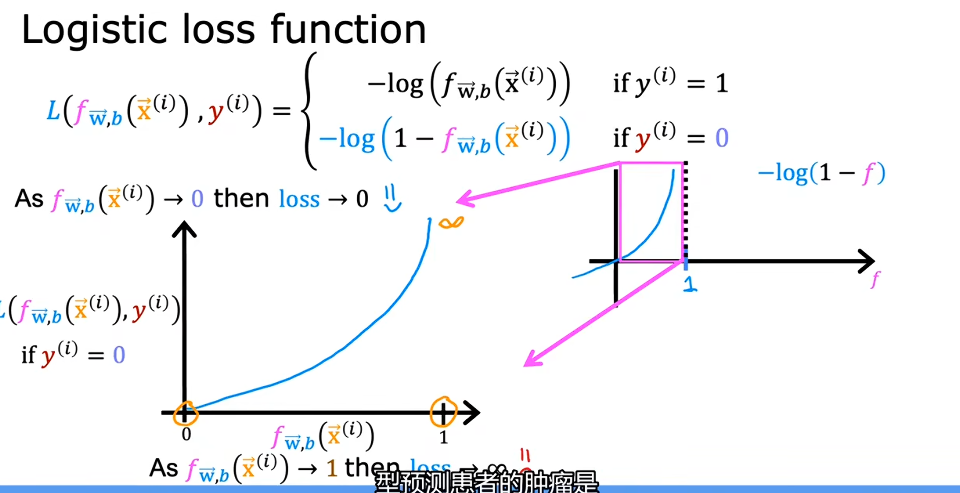
简化逻辑回归
可以进行简化如下:
非常巧妙,当取不同的值时(0或1),损失函数自动变为原本对应的分支。
所以代价函数:$$J(\vec{w},b)=\frac{1}{m}\sum_{i=1}m[L(f_{\vec{w},b}(\vec{x}),y^{(i)})]$$
这里可以注意到没有,是因为损失函数是一个一次的,所以求导时不会出现那个2,也就不用抵消了 。
梯度下降公式计算:
- 核心公式定义首先,我们需要明确几个基础组成部分:损失函数 (Log Loss):
预测函数 (Sigmoid):
- 求导步骤详解(链式法则)为了求 ,我们需要运用链式法则。我们以单一样本的损失 对某一个权重 求导为例:第一步:对 Sigmoid 函数求导 有一个非常优雅的特性:。即:。第二步:对 求导由于 ,那么:。第三步:对整体损失函数求导将上述部分组合起来,对单个样本的损失项求偏导:对 求导得到 对 求导得到 代入化简后:
- 最终结果将所有 个样本的导数累加并取平均值,就得到公式:
同理求出
跟线性回归的梯度下降函数居然一样,真的是这样吗?实际上不是的,因为两者的f已经发生了变化,线性回归的,逻辑回归的.
过度拟合(over fitting)
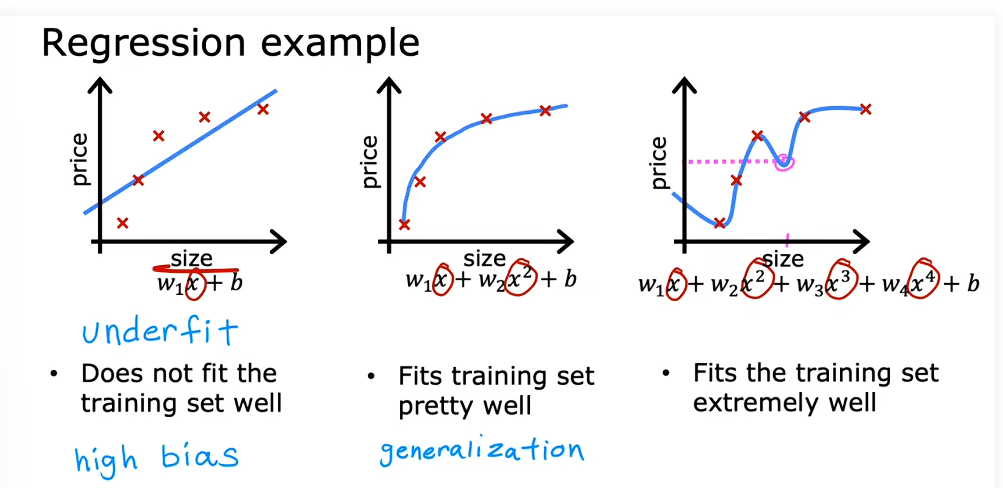
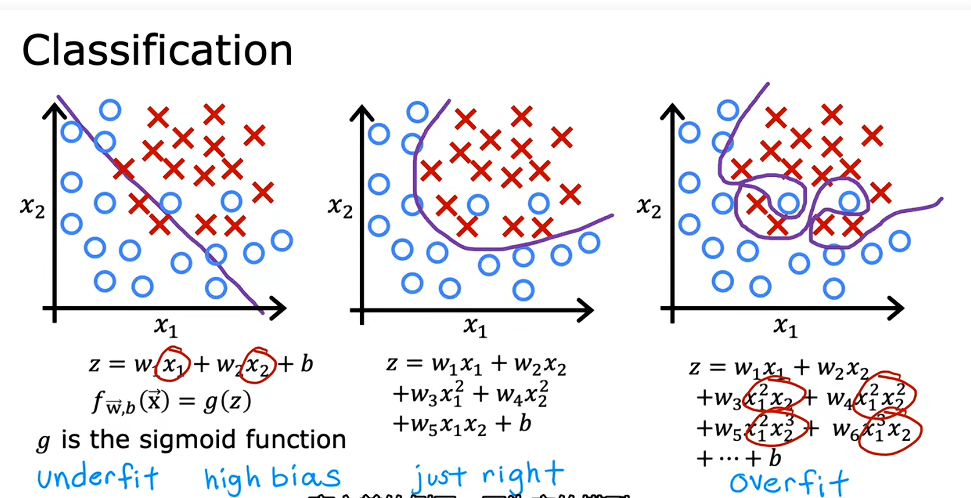
如上图,第三个模型的成本是0,即所有的点都落在了模型上,但是中间有波动,在某个位置房子大小变大但是房价减小,这并不符合实际,这就是过度拟合,过分的适合训练数据,但是如果再来一个外部数据,预测结果可能十分不尽人意。(高方差)
那么欠拟合则相反,最左边那个图,数据并不能够比较好的预测。(高偏差)
解决过度拟合
- 收集更多数据,使用更大的训练集
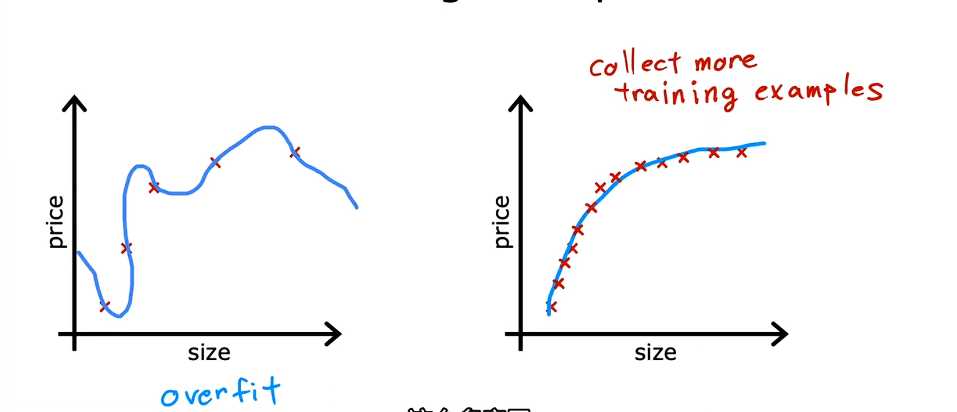 但是如果数据就只有这些,那么这个方法就不好用了。
但是如果数据就只有这些,那么这个方法就不好用了。 - 特征选择:使用更少的Features,如何选择更合适的,如何丢弃一部分无关紧要的特征,并不容易进行。并且太过苛刻,相当于直接把一个参数置为0,可以使用正则化来温和地缩小参数,这样就可以在不消除某个特征的基础上减小该特征的影响。
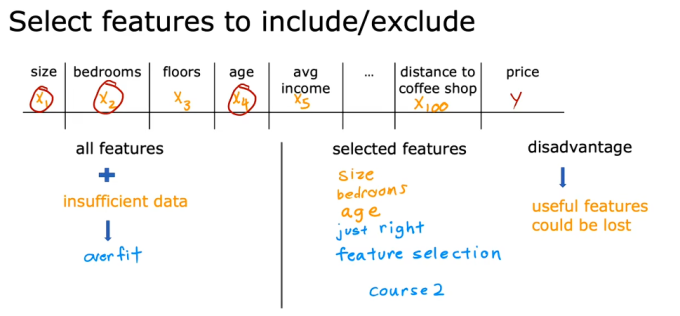
- 正则化:温和地鼓励算法减小参数,但不丢弃该特征。一般是减小参数,一般不会减小
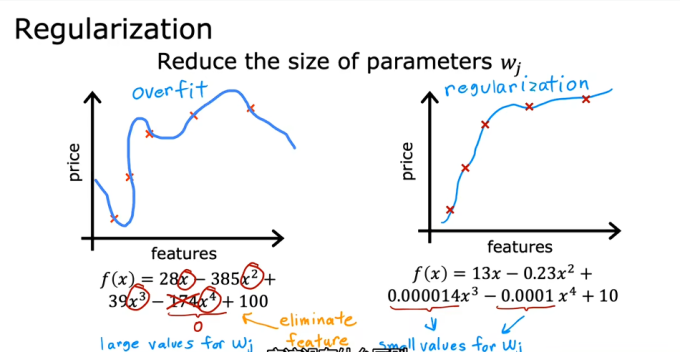
正则化
正则化的核心思想是:“不仅要结果准确,还要参数简单。”在没有正则化时,模型只追求损失函数(误差)最小。加入正则化后,我们给模型加了一个“紧箍咒”——惩罚项(Penalty)。公式的大致逻辑:
其中 (Lambda)是惩罚力度。如果模型想通过把参数变得特别大、特别复杂来拟合数据,总代价就会飙升。为了降低总代价,模型不得不保持参数“克制”。
代价函数就变为
后面将参数的平方和也作为惩罚项,防止参数过大。的选择也要合理,如果选为0,则与原来的代价函数一致容易继续过拟合,如果过大,学习算法则会让参数都接近零,model就会接近常数b,要合适的选择
常见的两种“紧箍咒”
- L1 正则化 (Lasso)做法: 把所有参数的绝对值加起来。特点: 它非常狠,会直接把一些不重要的参数变成 0。效果: 相当于自带“特征选择”,最后只剩下几个最有用的特征。就像断舍离,把没用的东西全部扔掉。
- L2 正则化 (Ridge)做法: 把所有参数的平方和加起来。特点: 它比较温柔,不会把参数变 0,但会逼着参数尽量变小(趋近于 0)。效果: 这样模型就不会过度依赖某一个特征,结构更加平滑、稳健。就像是把尖锐的棱角磨平,让模型更有包容力。
线性回归的正则化
我们已经知道了线性回归正则化的代价函数
要对其进行梯度下降
逻辑回归的正则化
深度学习(deep learning 也叫 neural networks、decision tree)
建立多层神经网络,是机器学习的延申
吴恩达老师一开始用人脑的神经元和深度学习的节点做了一个比较,要注意的是我们学的是算法,不用过分纠结取拟态人脑神经元。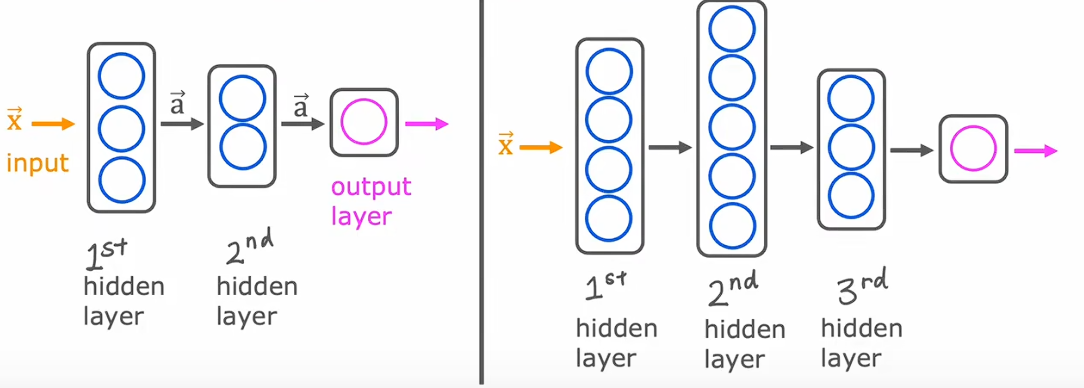
分为输入层,隐藏层和输出层。输入层即我们的features,隐藏层即中间层,可以有多层,有点类似特征工程,将多个特征转化为几个特征,最后输出一个预测数据。
人脸识别系统举例
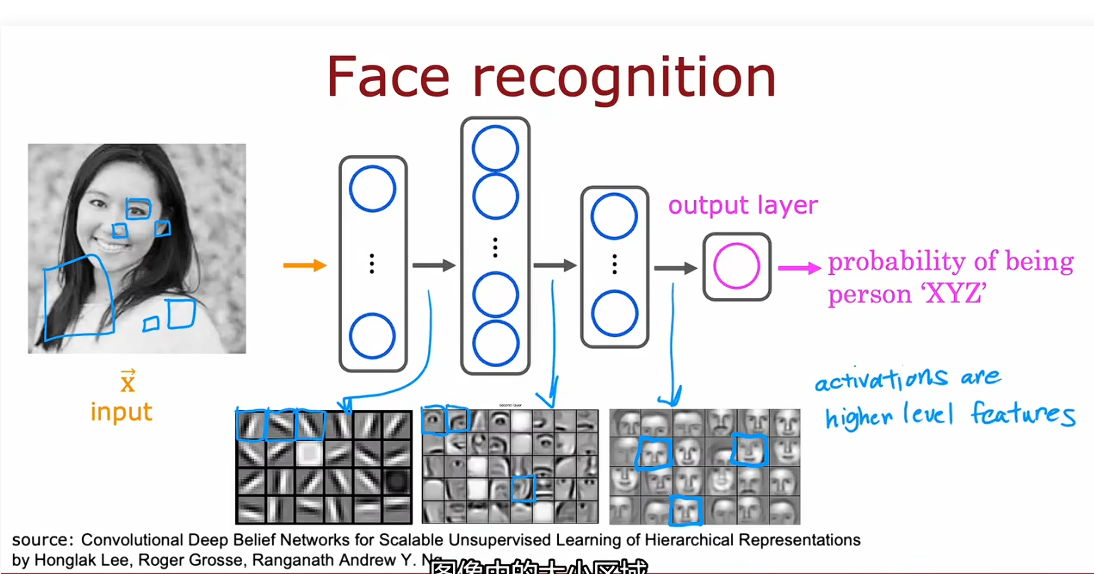
在这个例子中,吴恩达老师是这样说的。灰度图像(1000*1000像素的0-255的亮度值)作为输入,经过三层隐藏层,第一层提取小线条等边缘数据,第二层提取眼嘴鼻耳等局部特征,第三层读取面部,窗口逐渐扩大,最后输出。
神经网络中的网络层
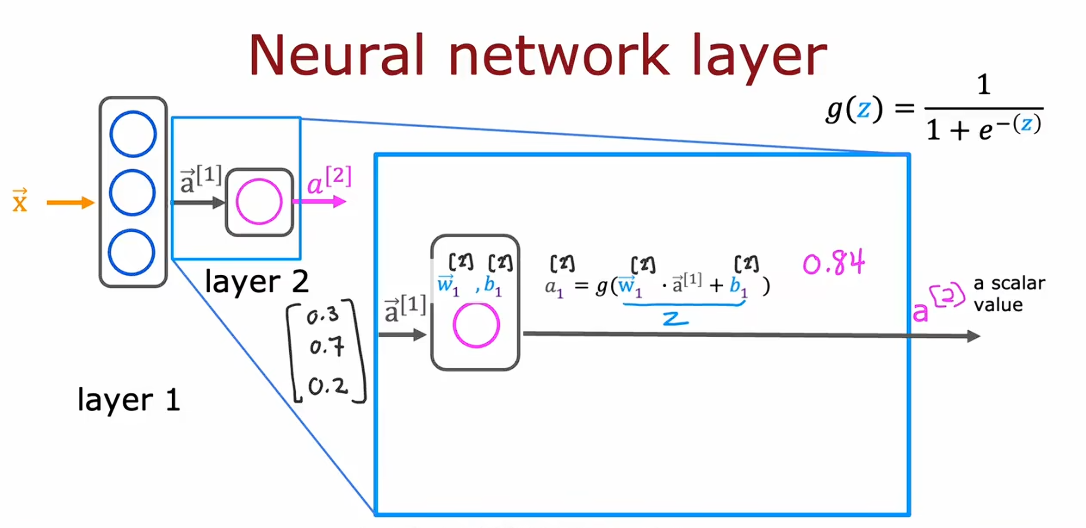
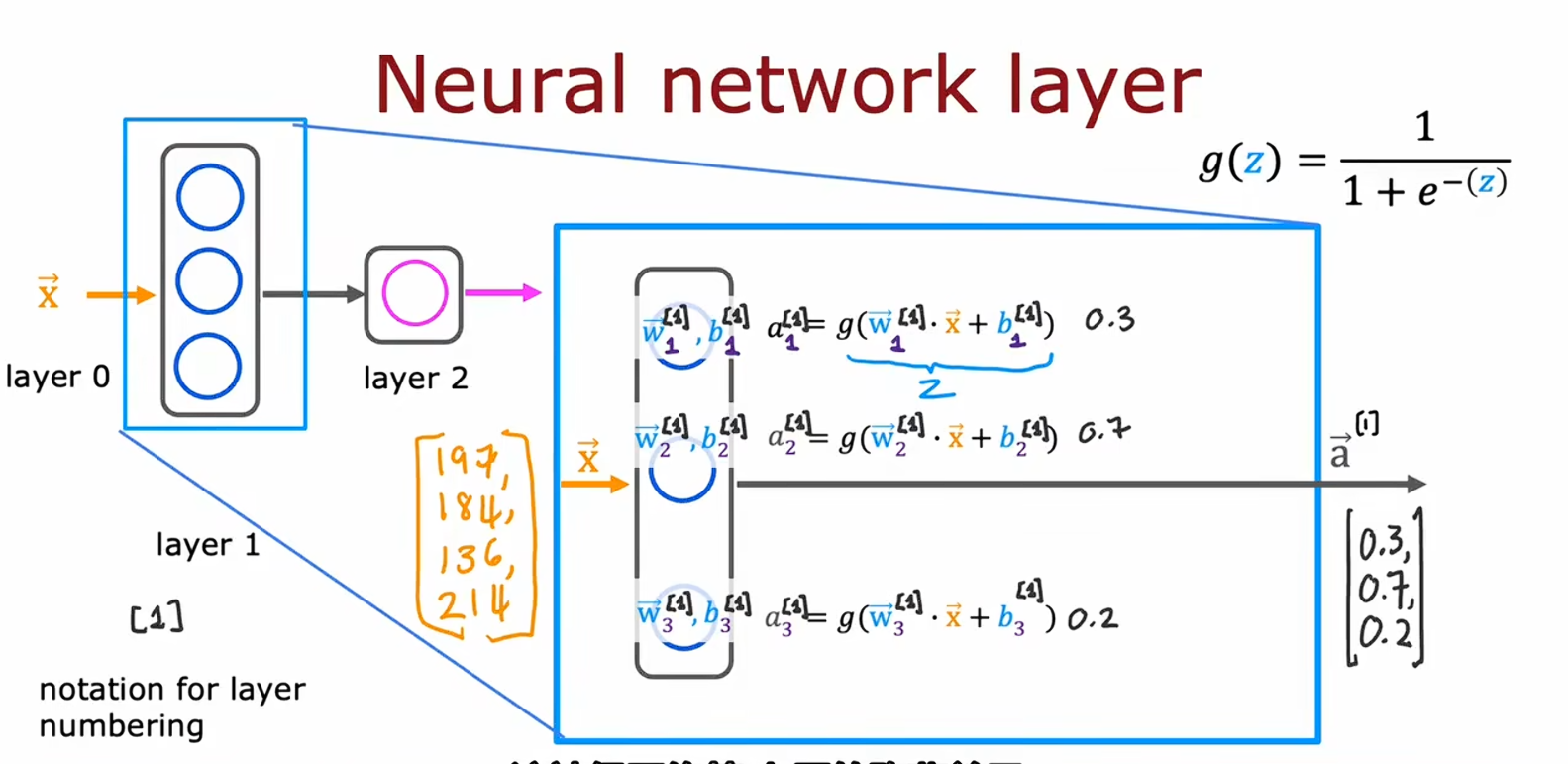
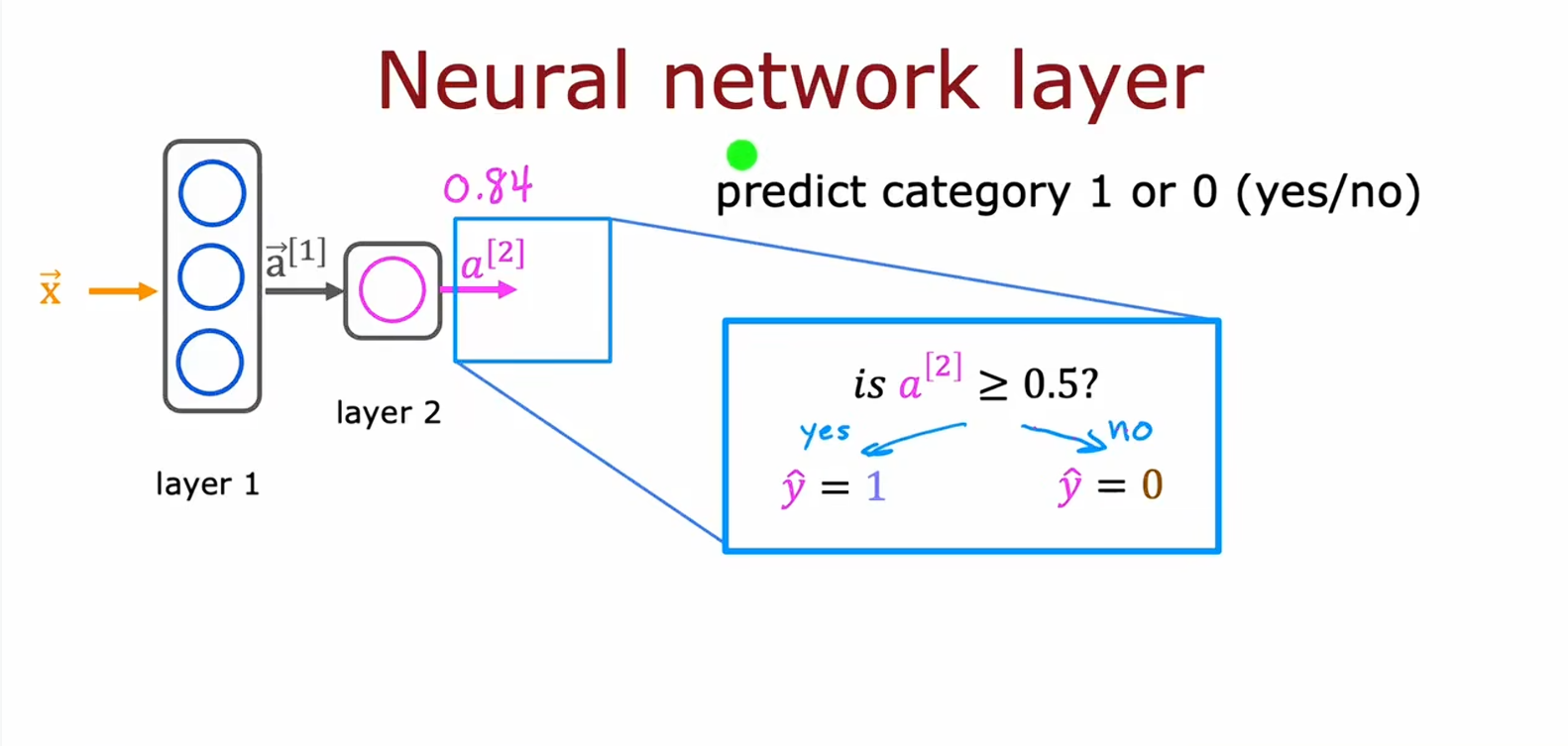
如上述经过两层然后阈值判断的三个流程
每一层中的节点都相当于一个函数,使用输入的向量计算出下一个输入的某个向量,这里的每层都用了sigmoid函数,最后输出做阈值判断。这里的[1]表示第几层的数据,有点类似于之前数据集中第i个数据带着(i)上标。
更复杂一点的网络
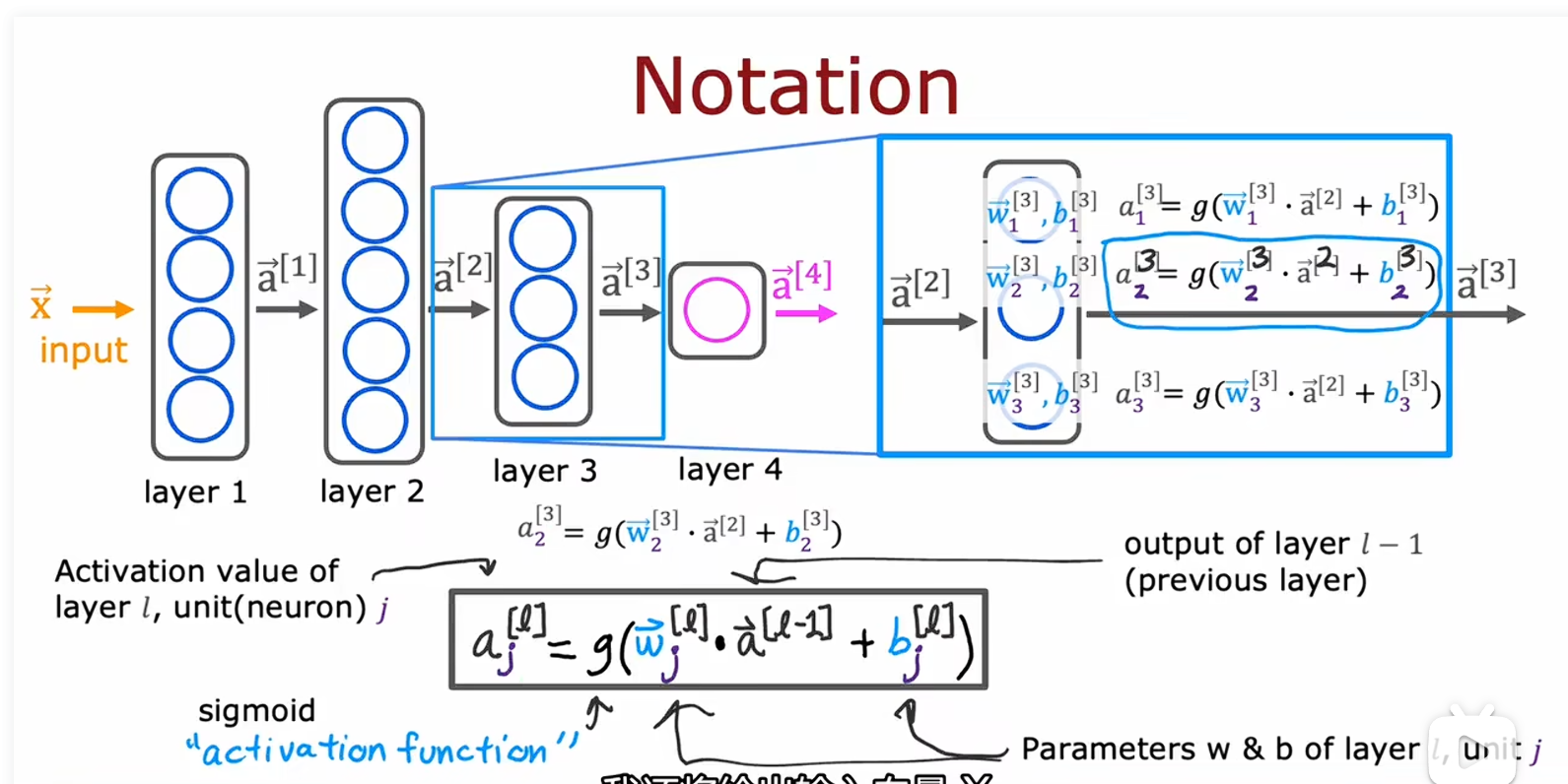
这里吴恩达老师给我们展示了一个更复杂的神经网络,有三层隐藏层,上一层的输出作为这一层的输入进行计算,这里的g表示的是激活函数,当前接触的是sigmoid函数。
神经网络的前向传播
其实没什么好说的,就是神经网络计算过程,一层一层前向计算最终得到输出。
代码实现神经网络
吴恩达老师在这里用的是TensorFlow框架,而不是pytorch,听一听学学思路,具体的pytorch使用可以看陶卓的。
强人工智能
AI:
- ANI(artificial narrow intelligence,狭义人工智能,专注于特定领域,过去十几年发展迅速)
- AGI(artificial general intelligence,通用人工智能,更能模仿人类思考)
神经网络为何这么高效(向量化矩阵运算)
复习一下线代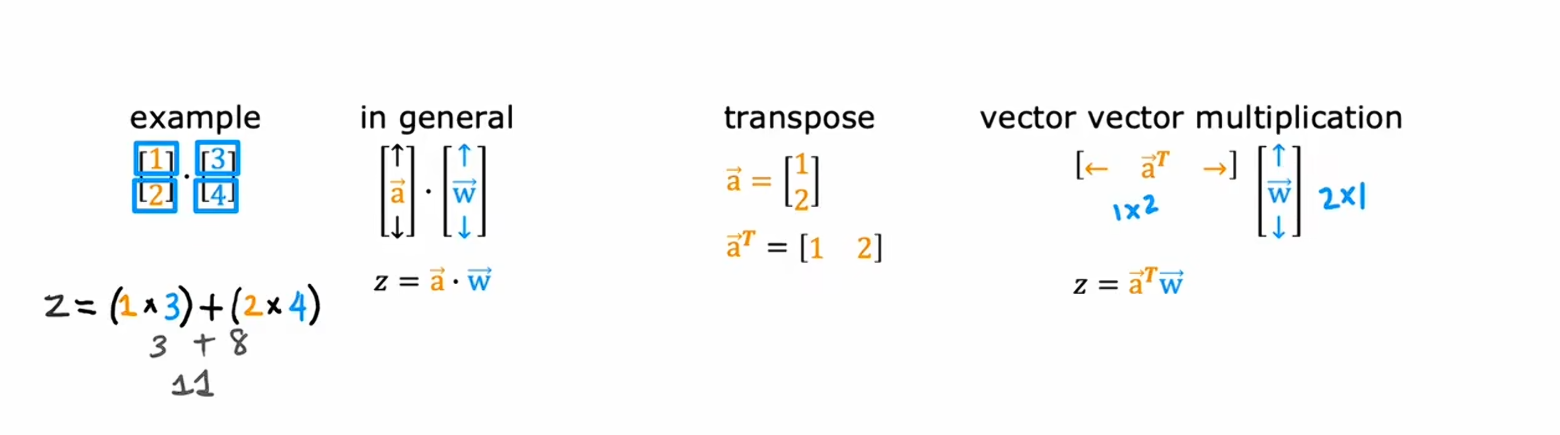
如上图点积操作: 各行相乘然后相加,得到的是一个数值
转置操作:将行列维度转换 用T上标表示转置后的向量,比如
注意区分向量和矩阵:
向量是一维数组,仅包含一个轴(如长度为 n 的向量称为 n 维向量),通常以列或行形式存储。
矩阵是二维数组,包含行和列两个轴,表示为 m×n 的表格形式。
向量运算主要包括点积、叉积以及标量乘法等。
矩阵运算则更为广泛,包括乘法、转置、求逆(仅方阵可逆)、行列式计算等。
如何选择激活函数使网络更加高效
sigmoid函数我们已经看过了,就是$$sigmoid(x) = \frac{1}{1 + e^{-x}}$$,这个函数大于0小于1;
还有一个常用的激活函数就是ReLu函数,即$$ ReLu(x) = max(0,x)$$,
当x小于等于0时为0,大于零时为原值
另外就是线性函数,没得说,g(x) = x
怎么选择呢
对于输出层的激活函数而言,如果输出是一个0或1的二分类问题,选择sigmoid函数;如果解决回归问题可能需要选择其他的,比方说预测明天股价跌还是漲,这个变化幅度是有正有负的,可以使用线性,如果是预测房价,那么房价只能是正的,可以使用ReLu。
对于隐藏层(中间层)而言,现在已经由sigmoid演变为ReLu,因为ReLu只会计算0或者x原值,计算更快,并且ReLu函数只有左侧平整,sigmoid左右两侧都平整,平整的地方梯度下降缓慢。
为什么要用激活函数
如果不用激活函数或者统统使用线性激活函数,因为每一层的每个神经元都是线性函数,那么线性函数的线性组合仍然是线性函数,所以没有效果。
多分类问题
softmax函数
Softmax 是一个“分配器”。它的作用是把一组杂乱无章的数值(比如 10、2、-5),转换成一组概率值(比如 0.8、0.15、0.05)。
在深度学习中,它通常出现在神经网络的最后一层,用来告诉我们:这件事属于某个类别的可能性有多大。
它做了哪两件大事?
要把普通数字变成概率,Softmax 必须完成两个任务:
变正数:不管原来的数是正还是负,经过它处理后,全部都会变成正数(0 到 1 之间)。
总和为 1:所有处理后的数字加在一起,必须等于 1(即 100%)。
打个比方:三个评委打分假设你参加了一场厨艺大赛,三个评委给你的作品打分(这就是所谓的 Logits):评委 A:4.0 分评委 B:1.0 分评委 C:-2.0 分(非常难吃)这时候,我们不能直接说你的得分就是概率,因为有负数,且总和不是 1。Softmax 会这样做:拉开差距:它先给每个分做一个指数运算()。高分会变得更高,低分会变得很小。4.0 变成了 54.61.0 变成了 2.7-2.0 变成了 0.1归一化:把这些新分数加起来,看每个分占总分的比例。总分:你的最终概率:评委 A 推荐率: 95.1%评委 B 推荐率: 4.7%评委 C 推荐率: 0.2%结果: 原本 4 分只比 1 分多 3 倍,但经过 Softmax,概率变成了约 20 倍。它让“强者更强”,让分类结果非常明确。
为什么叫 Softmax?
Max:它的目的是选出最大的那个(也就是得分最高的那一类)。Soft:它比较“温柔”。普通的 Max 会直接抹杀掉所有小分,只给最高分 100%,其余 0%。而 Softmax 会给失败者留一点点微小的概率,这在训练 AI 时非常重要,因为它能保留一点“错误的信息”,帮助模型不断修正。
数学长啥样?它的公式是:$$S_i = \frac{e{z_i}}{\sum_{j=1} e^{z_j}}$$:第 个原始得分。:把分变成正数并拉大差距。:所有分数的总和,用来做分母进行归一化。
多分类与 Softmax 的深度进阶
损失函数的选择:交叉熵
在二分类中我们用 BinaryCrossentropy,但在 0-9 数字识别这种多分类问题中,我们使用 SparseCategoricalCrossentropy(稀疏分类交叉熵)。
- 直观理解:如果正确答案是 "3",而模型预测 "3" 的概率 越大,损失值 就越小。
- 数学本质:当真实标签为 时,损失函数简化为:
数值稳定性:为什么用 from_logits=True?
在写 TensorFlow 代码时,你会发现一种“不直观”但更精确的写法。
- 普通写法:输出层用
Softmax激活 计算出概率 算出损失。 - 更优写法:输出层用
Linear(不设激活,输出 ) 在损失函数中设置from_logits=True。
为什么要这么麻烦? 因为 Softmax 涉及指数运算(),如果直接计算 ,当 很大或很小时,容易产生数值溢出或精度丢失。让 TensorFlow 把指数运算和对数损失函数“打包化简”,直接用 (即 logits)来计算,过程会更稳定、更准确。
优化算法与新层型
Adam 算法:智能自适应油门
传统的“梯度下降”像是一个固定步长的学步者,而 Adam (Adaptive Moment estimation) 更像是一个能自动换挡的老司机:
- 独立学习率:它并不只用一个全局 ,而是为每一个参数( 和 )都维护一个专属的学习率。
- 动态调整:如果某个参数的梯度一直指向同一个方向,它就加速(加大步长);如果方向来回摆动(震荡),它就减速(减小步长)。
代码实现:
optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3)
卷积层 (Convolutional Layer)
之前学的叫“全连接层/密集层”(Dense Layer),每个神经元都要看上一层的所有像素,计算量巨大。卷积层则换了思路:
- 局部视野:每个神经元只盯着图像的一个小区域(比如 3x3 或 5x5 的窗口)。
- 优势:计算快,参数量骤减;具备平移不变性,无论特征在图像哪个位置都能抓到,且不容易过拟合。
反向传播 (Backpropagation) 的本质
神经网络的训练其实就是两步循环:
- 前向传播 (Forward Prop):从左到右,一层层计算,最后得出一个预测值和总损失 。
- 反向传播 (Backward Prop):从右到左,利用链式法则计算总损失 对每一个微小参数()的偏导数。
为什么它高效?
如果针对每个参数都去微调一下看结果(数值微分),计算量是节点数与参数数的乘积。而反向传播通过从输出端向输入端“倒着走”,利用已经算好的中间梯度,计算量大大降低,这让训练拥有数百万参数的深度模型成为了可能。
总结:手写数字识别全流程
- 输入:20x20 像素图片(拉平成 400 维向量)。
- 隐藏层:使用 ReLU 激活,提取从线条到局部形状的特征。
- 输出层:10 个神经元(对应数字 0-9),使用 Linear 激活。
- 编译配置:Adam 优化器 + SparseCategoricalCrossentropy(from_logits=True)。
机器学习诊断与改进策略
如何科学地改进模型
当一个机器学习模型(如正则化线性回归)表现不如预期时,盲目收集数据往往是最低效的。在动手之前,我们需要先通过“诊断”来确定问题所在。常见的改进方向包括:
- 解决高方差(过拟合):增加训练样本数量、减少特征数量、增大正则化参数 。
- 解决高偏差(欠拟合):增加特征数量、添加多项式特征、减小正则化参数 。
训练、验证与测试集的拆分
为了准确评估模型的泛化能力并进行决策,我们需要将原始数据进行“三拆分”:
- 训练集 (Train set):用于训练模型参数 和 。
- 验证集 (CV/Dev set):这是模型选择的“主战场”,用于挑选多项式次数、神经网络层数或寻找最优的正则化参数 。
- 测试集 (Test set):仅在最终环节使用,用于给出一个不带偏见的泛化误差估计。它绝不参与任何参数的选择过程。
偏差与方差的深度诊断
误差分析与拟合判断
通过比较训练误差 和验证误差 ,我们可以快速定位模型状态:
- 欠拟合(高偏差): 很高,且 与 接近。说明模型根本没学会。
- 过拟合(高方差): 很低,但 远大于 。说明模型只会死记硬背。
- 偏差方差并存: 高且 远高于 ,这在复杂的神经网络中偶尔会出现。
引入性能基准
判断误差“高”还是“低”不能凭感觉,需要一个基准 (Baseline)。常见的基准包括人类的表现水平或已有的算法模型。
如果模型误差远高于基准,核心矛盾就是“高偏差”;如果模型误差接近基准但验证集误差远超模型误差,核心矛盾则是“高方差”。
学习曲线的启示
通过绘制误差随训练样本数 变化的曲线,可以发现:
- 在高偏差场景下,一味增加样本数是徒劳的,因为曲线会很快趋于平缓,误差始终无法降到基准线下。
- 在高方差场景下,增加样本数通常是有益的,它能帮助缩小训练误差与验证误差之间的鸿沟。
机器学习项目的工程技巧
误差分析与数据增强
在模型迭代中,手动检查错误样本是极具价值的。通过观察验证集中被分类错误的样本(如垃圾邮件分类中的药品类、拼写错误类),可以确定研发的优先级。
当确定需要更多数据时,有两种高效方案:
- 数据增强:对现有图片进行旋转、缩放、扭曲,或给音频加入背景噪音,人工制造出新的训练示例。
- 合成数据:从零开始构建数据,例如在字符识别中,利用计算机字体库结合人工干扰合成模拟真实的拍摄照片。
迁移学习:站在巨人的肩膀上
如果你的数据集非常小,可以尝试迁移学习。借用别人在大型数据集(如 ImageNet 或 GPT)上预训练好的模型,保留其特征提取的隐藏层,只更换并重新训练输出层。这种“知识迁移”在输入特征类型相同时(如都是图像或都是语音)效果显著。
机器学习系统的生命周期
一个完整的项目不仅包括训练。从确定范围、收集数据到训练迭代,最关键的是最后的部署与运维。
- 部署:通常将模型放在推理服务器上,通过 API 供 APP 调用。
- 运维 (MLOps):监控系统在真实世界中的表现,一旦环境发生变化(数据漂移),需要及时回溯并更新模型。
处理倾斜数据集与伦理规范
准确率与召回率的权衡
在正负样本比例极度失衡(如罕见病检测)时,单纯的准确率是具有误导性的。我们需要引入:
- 准确率 (Precision):在所有预测为阳性的样本中,有多少是真的。
- 召回率 (Recall):在所有真实的阳性样本中,我们成功找出了多少。
- F1 Score:通过计算两者的调和平均数 ,我们可以用一个指标来综合评估模型,帮助我们在“不冤枉好人”与“不放过坏人”之间找到最佳平衡点。
伦理与公平性
作为算法工程师,必须时刻警惕模型可能带来的偏见(如性别歧视、种族歧视)。
- 缓解计划:组建多元化开发团队,并在系统上线前进行自我审查。
- 职业操守:技术应服务于社会,拒绝开发 AI 换脸诈骗、煽动性言论推送等违背道德底线的项目。
决策树:像人类一样做决策
决策树是一种模拟二叉逻辑判断的非线性模型,通过一系列“是/否”的问题,将数据从顶部的根节点引向底部的叶子节点(预测结果)。在构建决策树时,核心挑战在于如何选择每一层的拆分标准以及何时停止生长,以避免模型过于复杂导致过拟合。
核心指标:熵与信息增益
为了量化“哪种拆分更好”,我们引入**熵(Entropy)**来衡量数据的“纯度”或“混乱度”。
- 熵的概念:如果一个集合里全是猫,熵为 0;如果猫和非猫各占一半,熵达到最大值 1。
- 信息增益(Information Gain):它是拆分前后的熵差值。我们目标是找到一个特征,使得拆分后的加权平均熵最小,从而获得最大的信息增益。
适配不同类型的特征
决策树不仅能处理简单的“是/否”特征,还能通过转换适配更复杂的数据:
- 多元分类特征:通过 独热编码(One-hot Encoding) 将拥有多个取值的特征(如:颜色有红、绿、蓝)转换为多个二元特征。
- 连续值特征:通过寻找最佳阈值(如:重量 > 9kg),将连续数值切分为二元逻辑。
- 回归任务:对于连续的输出值,我们不再计算熵,而是计算**方差(Variance)**的减少量,最终叶子节点的预测值为该簇样本的平均值。
决策树的递归构建逻辑
构建单个决策树的过程本质上是一个递归过程:
- 计算所有剩余特征的信息增益。
- 选择增益最大的特征进行拆分。
- 对拆分出的子集重复上述步骤,直到满足停止条件(如:达到最大深度、熵为 0 或样本数太少)。
从单棵树到决策树集合(森林)
单棵决策树对数据非常敏感,微小的样本变动就可能导致树的结构巨变。为了提高鲁棒性和准确性,我们通常使用集成学习(Ensemble Learning)。
随机森林 (Random Forest)
随机森林通过两层“随机”来增加多样性:
- 有放回抽样(Bagging):每次从原始数据中随机抽取样本(允许重复),构建不同的训练集。
- 特征随机化:在每个节点拆分时,只从随机选取的特征子集中挑选最佳特征。
这种“众议院”式的投票机制大大降低了过拟合风险。
XGBoost:算法界的“刷题专家”
XGBoost (Extreme Gradient Boosting) 是目前工业界最常用的版本。它的核心思想是增强(Boosting):
- 它不是并行独立建树,而是顺序建树。
- 每一棵新树都专注于弥补上一棵树预测错的样本(类似“错题本”和“刻意练习”)。
XGBoost 运行速度极快,内置正则化,是处理结构化数据(如表格数据)的首选神器。
决策树 vs 神经网络:如何抉择?
在实际项目中,选择哪种算法取决于数据的性质:
优先选择 决策树集合 (如 XGBoost):
- 数据类型:结构化数据(电子表格、数据库记录)。
- 优势:训练极快,对人类可解释性强,不需要复杂的特征缩放。
优先选择 神经网络:
- 数据类型:非结构化数据(图像、视频、音频、文本)。
- 优势:支持迁移学习,可以将多个模型串联,处理超大规模数据的能力更强。
总结
决策树家族(尤其是随机森林和 XGBoost)凭借其在结构化数据上的卓越表现和高效的训练速度,成为了机器学习工具箱中不可或缺的一部分。掌握了熵、信息增益以及集成学习的思想,你就拥有了处理大多数商业数据分析问题的利器。
无监督学习:探索无标签数据的内在结构
在有监督学习中,我们拥有标签 来指导模型;而在无监督学习中,我们只有特征 。算法的任务是自主发现数据中的模式、结构或聚类。本章重点探讨两种最广泛的商业应用:聚类 (Clustering) 与 异常检测 (Anomaly Detection)。
K-means 聚类算法
K-means 是处理无标签数据最常用的算法,它能够自动将相似的样本归为一类。无论是基因分类、客户分群,还是设计 T 恤的尺码,K-means 都能提供直观的分组方案。
算法运作逻辑
K-means 通过不断迭代“分配”与“移动”两个步骤来寻找最优质心:
- 分配步骤:遍历每个样本 ,计算它到 个质心的距离,并将其分配给距离最近的质心 。
- 移动步骤:计算每个簇内所有样本点的平均值,并将该簇的质心 移动到这个平均中心。
- 收敛:重复上述过程,直到质心位置不再发生变化。
代价函数与失真 (Distortion)
K-means 实际上是在最小化样本与其对应质心之间的平方距离之和。其代价函数(也称失真函数)定义为:
其中 是样本 被分配的质心索引。每次迭代,这个代价函数都会下降或保持不变。
避免局部最优
随机初始化质心可能导致算法陷入局部最优(聚类结果不合理)。
- 解决方案:多次随机初始化(运行 50-100 次),计算每次最终的代价 ,选择总代价最低的那次结果。
聚类数量 的选择
- 肘部法则 (Elbow Method):绘制代价 随 变化的曲线,寻找下降速度明显变缓的“拐点”。
- 面向需求:根据后续业务逻辑决定。例如,如果业务需要 3 种尺码的 T 恤,那么 就是最合理的。
异常检测算法
异常检测旨在学习什么是“正常”,从而识别出不符合常规模式的样本。它广泛应用于飞机引擎故障检测、金融诈骗监测和服务器状态监控。
概率密度估计 (Density Estimation)
我们假设数据的各个特征服从高斯分布(正态分布)。通过训练集学习正常样本的概率分布 ,对于新样本:
- 如果 ,判定为异常(Anomaly)。
- 如果 ,判定为正常(Normal)。
数学模型:高斯分布
对于单个特征,其概率密度函数为:
对于具有 个特征的样本,我们假设特征间相互独立(即使不完全独立,算法依然稳健),联合概率为:
异常检测 vs. 有监督学习
- 选择异常检测:当正样本(异常)极少(0-50个),而负样本(正常)很多;且异常类型千奇百怪,未来可能出现从未见过的异常模式。
- 选择有监督学习:当正负样本都非常充足,且未来的异常模式通常已经在训练集中出现过(如垃圾邮件分类)。
特征工程的关键技巧
在异常检测中,特征的选择至关重要:
- 非高斯特征转换:如果原始分布看起来不像钟形,可以尝试取对数 、取根号或进行幂次变换 。
- 误差分析:如果某个异常样本被误判为正常,检查它在哪个维度上显得特殊,或者通过组合旧特征(如 )来创造一个能显著区分异常的新指标。
实战案例:图像压缩与系统监控
K-means 图像压缩
通过将图像中的数万种颜色聚类为少数几种(如 16 种),我们可以只存储这 16 个质心的颜色值和每个像素点的索引,从而大幅减小图像的存储体积。
自动化异常监测
在数据中心监控中,异常检测算法能同时分析 CPU 使用率、内存占用、磁盘 I/O 和网络流量。它不仅能发现单个指标的极端值,还能捕捉到多个指标组合出的潜在异常行为。
总结
- 聚类帮助我们在混乱的无标签数据中发现隐藏的群体。
- 异常检测利用统计学概率分布为系统安全和质量控制提供保障。
- 核心建议:在聚类中关注 的业务意义;在异常检测中投入更多精力进行特征变换和误差分析。
推荐系统:连接用户与产品的算法奥秘
推荐系统是机器学习最成功的商业应用之一。它不仅能提升用户体验(猜你喜欢),更是电商、流媒体平台的核心利润引擎。本章深入探讨两种主流算法:协同过滤与基于内容的过滤,并介绍数据降维神器 PCA。
协同过滤算法 (Collaborative Filtering)
协同过滤的核心逻辑是:根据和你相似的用户偏好来推荐内容。它不需要知道电影的具体属性,而是通过大众的打分行为“协同”推导出电影特征和用户偏好。
算法演进逻辑
- 已知电影特征推导用户参数:如果已知电影的“浪漫度”和“动作度”(特征 ),可以通过线性回归拟合出用户的口味参数 。
- 已知用户参数推导电影特征:如果已知用户的口味,可以通过他们的打分反推电影的属性。
- 协同计算 (Simultaneous Learning):在现实中两者均未知。协同过滤通过一个联合代价函数,同时优化电影特征 和用户参数 。
核心数学表达
其联合代价函数为:
算法通过 Adam 优化器 在 TensorFlow 中使用 tf.GradientTape() 自动计算梯度并同时更新这些参数。
均值归一化 (Mean Normalization)
- 冷启动问题:对于从未打分的新用户,其参数会被正则项压制为 0,导致预测评分全为 0。
- 对策:先计算每部电影的平均分 ,将所有评分减去均值进行训练。预测时再加回均值。
- 效果:新用户的初始预测分将等于电影的平均分,而非零,从而实现了基础推荐。
基于内容的过滤 (Content-based Filtering)
与协同过滤不同,基于内容过滤通过用户画像与产品特征的匹配度进行推荐。它更擅长利用用户的年龄、性别以及电影的类型、演员等显式信息。
双塔神经网络架构 (Two-tower Model)
该模型使用两个平行的神经网络将原始特征映射到同一个特征空间:
- 用户网络:输入用户原始特征 ,输出用户向量 。
- 项目网络:输入电影原始特征 ,输出电影向量 。
- 匹配计算:预测评分即为两个向量的点积:$$\hat{y}^{(i,j)} = \vec{v}_u^{(j)} \cdot \vec{v}_m^{(i)}$$
检索与排名 (Retrieval & Ranking)
面对海量数据,系统采用两步走策略以保证秒级响应:
- 检索 (Retrieval):快速从百万级库中筛选出几百个候选项目(如:根据最近观看历史寻找相似电影)。
- 排名 (Ranking):对候选列表进行精确的神经网络评分排序,最终展示给用户。
推荐系统的伦理与挑战
算法并非绝对中性,开发者需要关注:
- 信息茧房:用户只看到自己感兴趣的内容,导致认知收缩。
- 算法偏见:由于原始数据偏差,推荐可能带有群体歧视。
- 利益权衡:公司可能为了点击率而推送极端的或高利润但低质量的内容。
选修:主成分分析 (PCA)
PCA 是一种强大的无监督学习算法,主要用于数据降维、可视化和压缩。
PCA 的核心原理
PCA 并不是简单的特征舍弃,而是寻找一组新的相互垂直的坐标轴(主成分):
- 第一主成分:样本在这一方向上的方差最大,保留了最多的原始信息。
- 最大化方差:PCA 寻找一个低维平面,使得数据投影到该平面后的方差最大,同时最小化投影误差。
应用场景
- 可视化:将 100 维的特征压缩到 2D 空间,观察样本的聚类趋势。
- 数据预处理:减少特征冗余,在不显著损失精度的情况下大幅提升后续算法的运行速度。
算法对比总结
| 特性 | 协同过滤 (Collaborative) | 基于内容过滤 (Content-based) |
| : | : | : |
| 核心逻辑 | 相似用户喜欢什么,你就喜欢什么 | 你过去喜欢什么特征,就推荐什么特征 |
| 冷启动 | 表现较差(依赖历史打分) | 表现较好(依赖显式画像) |
| 特征需求 | 不需要知道产品具体属性 | 需要深入了解用户和项目特征 |
| 实现工具 | 矩阵分解、Adam 优化 | 深度学习、向量点积 |
强化学习:构建自主决策的智能体
强化学习(Reinforcement Learning, RL)是机器学习的三大支柱之一。与有监督学习不同,我们不告诉模型“正确答案”,而是通过**奖励函数(Reward Function)**来引导智能体(Agent)在环境(Environment)中通过试错来寻找最优策略。
强化学习的核心要素
强化学习可以抽象为智能体与环境的持续交互过程,其数学基础是马尔可夫决策过程(MDP)。
- 状态 (State, ):智能体所处的当前情况(如机器人的关节角度、飞机的坐标)。
- 动作 (Action, ):智能体在特定状态下采取的行为(如向左移动、增加油门)。
- 奖励 (Reward, ):环境对动作的即时反馈。正奖励鼓励行为,负奖励(惩罚)抑制行为。
- 折扣因子 (Discount Factor, ):取值在 之间,用于权衡即时奖励与长期回报。 越接近 1,智能体越有“远见”。
离散状态空间的强化学习
在离散空间中(如简单的格子世界或棋盘游戏),我们可以通过计算 Q 函数 来找到最优动作。
回报 (Return)
回报是未来所有奖励的加权总和:
贝尔曼方程 (Bellman Equation)
贝尔曼方程是强化学习的灵魂,它揭示了当前状态价值与未来状态价值之间的递归关系:
- 物理意义:在状态 采取动作 的价值 = 当前获得的即时奖励 + 经过折扣的下一状态 的最优预期价值。
连续状态空间的强化学习:深度 Q 网络 (DQN)
当状态空间是连续的(如登月器的坐标和速度是无限细分的实数),我们无法用表格列出所有 值,必须使用神经网络来拟合 Q 函数。
DQN 算法原理
DQN 将状态 作为输入,输出该状态下所有可能动作的 值预测。
- 训练目标:使神经网络预测的 逼近贝尔曼方程计算的目标值 :
- 损失函数:使用均方误差(MSE)最小化预测值与目标值 之间的差距。
算法改进的关键技术
为了让强化学习更稳定、高效,现代 DQN 引入了以下优化:
-贪婪策略 (-greedy):
- 以 的概率选择当前最优动作(利用/Exploitation)。
- 以 的概率随机选择动作(探索/Exploration)。
- 这能保证智能体不会因为初期的错误认知而陷入局部最优,保持对未知路径的尝试。
经验重放 (Experience Replay):
- 将智能体的经历 存入重放缓冲区(Replay Buffer)。
- 训练时从中随机抽取**小批量(Mini-batch)**数据。这能打破样本间的时间相关性,使神经网络训练更符合独立同分布假设。
目标网络与软更新 (Target Network & Soft Update):
- 使用两个结构相同的网络: 网络(用于高频更新)和目标 网络(用于稳定目标值)。
- 软更新:不再直接覆盖参数,而是按比例缓慢融合:$$Q_{target} = \tau Q + (1-\tau) Q_{target}$$(其中 通常取极小值,如 0.001)。这有效防止了训练过程中的参数剧烈振荡。
强化学习的应用与局限
适用场景
- 机器人控制:登月器软着陆、双足机器人平衡、无人机特技飞行。
- 博弈策略:AlphaGo、星际争霸等复杂电子游戏。
- 工业调度:数据中心能效管理、自动化仓储路径规划。
局限性
- 样本效率低:通常需要数万次甚至百万次的仿真(Episodes)才能学会简单动作。
- 参数极度敏感:折扣因子 、探索率 的微小变动可能导致模型完全不收敛,这被称为“玄学炼丹”。
- 仿真与现实的鸿沟 (Sim-to-Real):在模拟器中表现完美的算法,部署到真实环境时常因摩擦力、传感器延迟等物理因素而失效。